Written by: Michael Mozer, Scientific Advisor at AnswerOn and Professor at the University of Colorado
A decade ago, AnswerOn often analyzed data sets with several million records. At the time, these data sets were about as large as one could feasibly model with sophisticated machine learning methods. Now we’ve entered the “big data” era. Most of us who have been analyzing and interpreting data sets for decades are slightly annoyed by the “big data” terminology, but there does appear to be something new going on with internet-scale data sets that contain billions of records.
The opinion often expressed by big-data evangelists is that all you need is data: with enough data, any problem can be tackled. The hope is that neural networks can serve as a general-purpose “black box” algorithm for classification and prediction. These evangelists claim that understanding the problem domain isn’t necessary; all we need are massive quantities of data. To illustrate this point, consider the red curve below, which is a hypothetical relationship between the amount of data available for training a model and the model’s prediction accuracy.
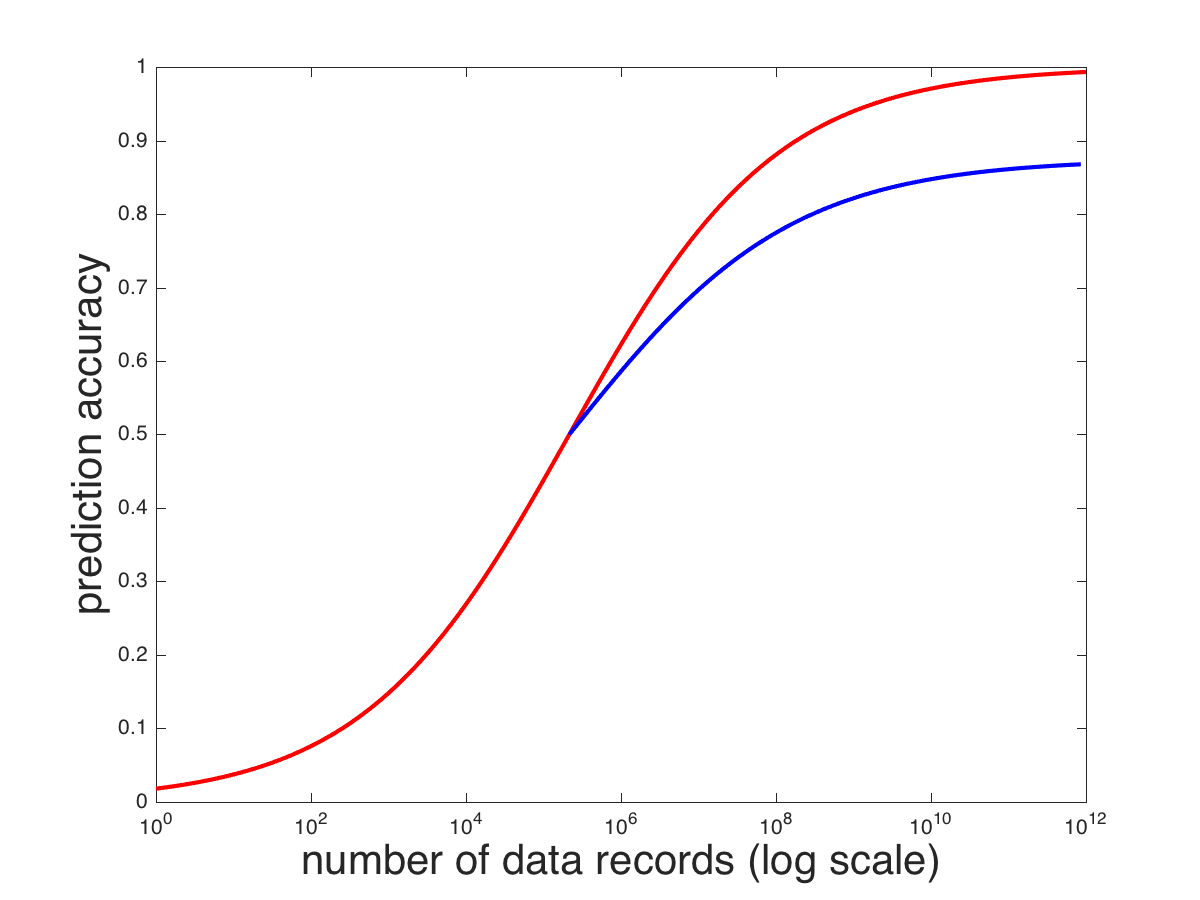
Models improve as the amount of data grows. When we operated with data sets containing hundreds or thousands of records, it was certainly true that more data would improve performance. But we cannot guarantee a rate of improvement. We also cannot determine in advance where the model will asymptote, that is, at what level of performance it will stop improving. It’s natural to suppose that with infinite data, the model will have perfect prediction accuracy, but this isn’t always the case because some information needed for accurate prediction is unavailable. For example, you can’t possibly predict the exact temperature in 2 weeks from today knowing only the temperature today. Nonetheless, the more historical data we have from the same day of the year, the better we expect our prediction to be. The prediction problems tackled by AnswerOn are challenging because the information being used for prediction is so sparse. For example, in predicting call-center agent churn, we may have a dozen agents who work in the same call center, have worked for the same length of time, and who look otherwise identical in terms of the features we have available for prediction. However, one agent may have a family crisis, another may slip and fall. With no information in the data set to tell us about these situations, the agents cannot be distinguished from the others, and 100% accuracy of prediction is not attainable. Turning back to the graph above, even with millions of records of data, we can’t determine in advance whether prediction accuracy will scale up as the red curve or as the blue curve.
Many of the exciting advances in machine learning lately have come in the area of computer vision, i.e., in building systems that can interpret images and recognize objects. Computer vision is a very difficult problem, but in some sense it’s easier than call-center agent churn prediction because the input—an array of intensities of pixels—contains all the critical information needed for analysis. If a human can recognize an object in an image, there’s no reason in principle that a machine learning system shouldn’t be trained to perform just as reliably. Consequently, computer vision is one area where we might expect “big data” (or “big enough data”) to solve difficult problems. Some remarkable results have been obtained in recent years. For example, Google researchers have developed an end-to-end system that captions images (Vinyals, Toshev, Bengio, & Erhan, 2015). By “end-to-end”, I mean that it takes image pixels as input, and it is trained with images labeled with sequences of words. It starts off knowing nothing about images and nothing about language, and relies entirely on the data. Here are some examples of its performance:

How do we compensate for not having “big enough data” or for data sets that are missing some information critical to prediction?
We leverage knowledge of domain experts. Domain experts understand the problem being solved and based on their past experience. They can shape the data being fed into the model—the model’s input representation—as well as the specific characteristics of the prediction task. The importance of domain expertise is under appreciated in the big data era. Expert knowledge can substitute for data. Consider the two curves below. The red curve might represent how a generic model’s prediction accuracy improves with the amount of data. The green curve represents the same improvement, but using a model that is crafted by experts who understand the problem domain. The point of these hypothetical curves is that with finite data, a model that is crafted by experts will likely outperform a generic model that does not take the domain into consideration: compare performance of the red and green curves at the dashed line, which represents 1M data records.
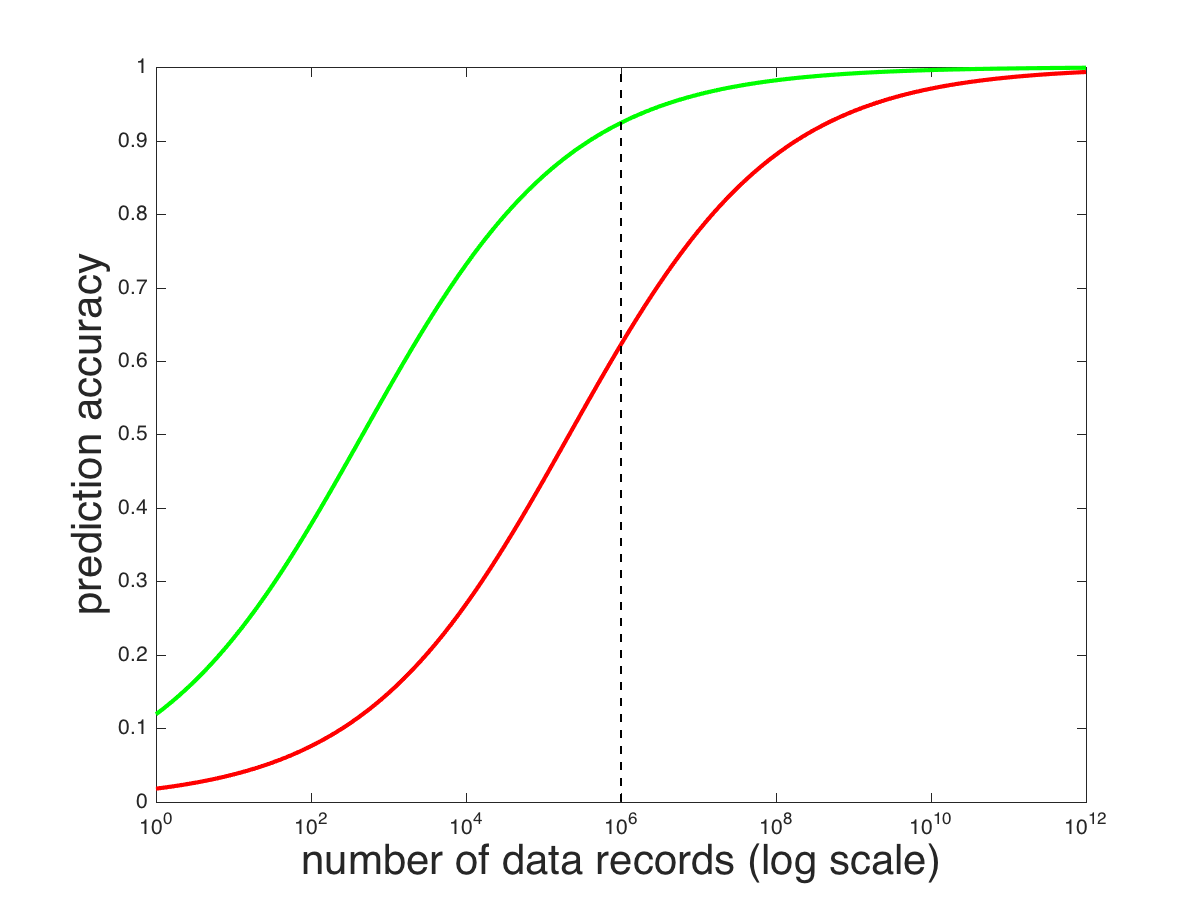
In my next posting, I’ll give some examples of how expertise is used to craft a model. Expertise isn’t used to hard-wire a solution; rather expertise is used to determine how to represent information being fed into the model. AnswerOn has many years of experience building models of churn prediction and churn remediation. This experience is critical to crafting as accurate a model as possible in the face of finite, noisy data.

